If you’ve wondered how assistants like ChatGPT or Copilot respond so quickly—even when powered by very large models—the reason is simple: they do not read your entire document, or even your full message, on every turn. They deliberately keep the effective prompt small. Using “sessional RAG” (session‑level retrieval‑augmented generation), they expand your query, fetch a few relevant snippets from an index of your content, blend in a thin slice of recent chat context, and send a compact prompt to the model. Small prompts are cheap and fast. That is the primary upside of these products’ default behavior: reduced latency and lower cost. The trade‑off is depth when the task truly needs broader context.
What a context window really is
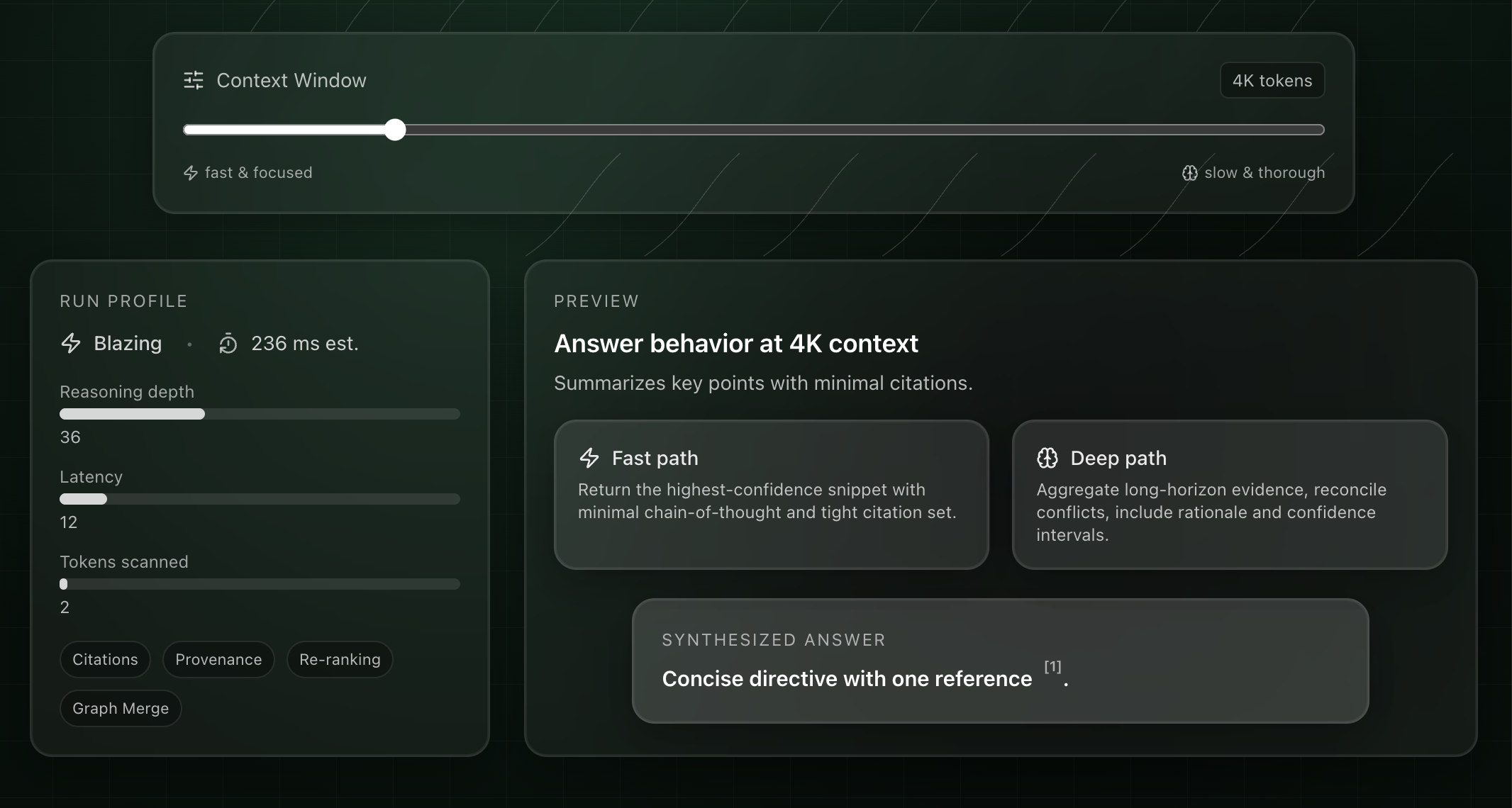
A context window is simply how much text (tokens) a model can consider at once. Bigger windows enable richer reasoning across long documents, but they cost more and take longer to run. Commercial assistants optimize for fleet‑wide responsiveness and budget, so they cap what actually reaches the model. Even when you upload a big file, the assistant usually retrieves and injects only a handful of chunks. That’s great for quick answers, but it truncates nuance, cross‑references, tables, and long‑range dependencies that matter in serious work.
This is why Microsoft positions Copilot as a grounded task assistant, not a bulk document processor. For whole‑document and multi‑document workflows, they point teams to Azure OpenAI and Azure AI Search patterns where you can control context and orchestration. See Microsoft 365 Copilot overview and grounding: https://learn.microsoft.com/microsoft-365-copilot/microsoft-365-copilot-overview and Azure OpenAI “use your data” concepts and limits: https://learn.microsoft.com/azure/ai-services/openai/concepts/use-your-data. The message is consistent: keep Copilot fast for everyday help; use Azure patterns when you need deep analysis.
When do larger context windows matter?
Any informationally intensive task where the model must hold global structure in mind: compliance reviews on long permits and contracts, cross‑document synthesis of reports and emails, regulatory change tracking, forensic timelines, architecture or codebase reviews, and executive briefings drawn from large, messy corpora. In these cases, small RAG snippets can miss critical context, produce inconsistent judgments, or force you into piecemeal workflows.
Unlocking full reasoning with a custom orchestrator
A custom orchestrator changes the game. Your conversation isn’t silently RAG‑compressed; instead, you can feed the full context window to the model—entire files, structured sections, or multiple documents—while deciding what to summarize and what to pass verbatim. You choose the model and window size, preserve document structure, and run advanced patterns like sliding windows or map‑reduce without losing fidelity. The result is slower and more expensive per call, but far more powerful for work that actually moves risk, cost, or revenue.
The practical takeaway is a two‑tier approach: use small, RAG‑optimized prompts for speed and convenience, and reserve large‑context runs for the moments that matter. Measure both. When the stakes are high, bigger context windows consistently unlock better, more defensible outcomes.